

Автор: Мяо Чжен
Google прикидався сплячим 8 місяців, а потім раптово випустив справжню бомбу — Gemini 3 Pro.
Google нарешті випустив Gemini 3 Pro — дуже несподівано і навіть "скромно".
Хоча перед цим Google презентував модель для редагування зображень Nano Banana, щоб нагадати про себе, у сфері базових моделей компанія мовчала занадто довго.
Останні півроку всі активно обговорювали нові кроки OpenAI або захоплювалися домінуванням Claude у сфері коду, але ніхто не згадував Gemini, який не оновлювався вже 8 місяців.
Навіть якщо хмарний бізнес Google і фінансові звіти виглядають чудово, у колі AI-розробників відчуття присутності Google поступово зникає.
На щастя, після першого досвіду використання, можу сказати, що Gemini 3 Pro нас не розчарував.
Але робити висновки ще зарано. Адже нинішній AI-ринок давно вийшов за межі змагання лише за кількістю параметрів — тепер усі змагаються у застосуваннях, впровадженні та вартості.
Чи зможе Google адаптуватися до нової версії та нових умов — питання відкрите.
01
Я попросив Gemini 3 Pro описати себе одним реченням, і ось що він відповів:
“Я більше не поспішаю доводити світу, який я розумний, а починаю замислюватися, як стати кориснішим.” — Gemini 3 Pro
У рейтингу LMArena Gemini 3 Pro очолив список із показником Elo 1501 — це новий рекорд у комплексній оцінці AI-моделей. Це дуже високий результат, навіть Альтман привітав у Twitter.

У тесті математичних здібностей модель досягла 100% точності в режимі виконання коду на AIME2025 (Американська математична олімпіада). У тесті GPQADiamond наукових знань точність Gemini 3 Pro склала 91,9%.
У тесті MathArenaApex змагання з математики Gemini 3 Pro набрав 23,4%, тоді як інші популярні моделі зазвичай мають менше 2%. Крім того, у тесті Humanity'sLastExam без використання інструментів модель досягла 37,5%.
У цьому оновленні Google представив функцію генерації коду під назвою “vibecoding”. Вона дозволяє користувачам описувати свої потреби природною мовою, а система генерує відповідний код і додатки.
У тесті середовища програмування Canvas, після опису “створити вентилятор з регулюванням швидкості обертання”, система за 30 секунд згенерувала повний код із анімацією обертання, повзунком швидкості та кнопкою увімкнення/вимкнення.
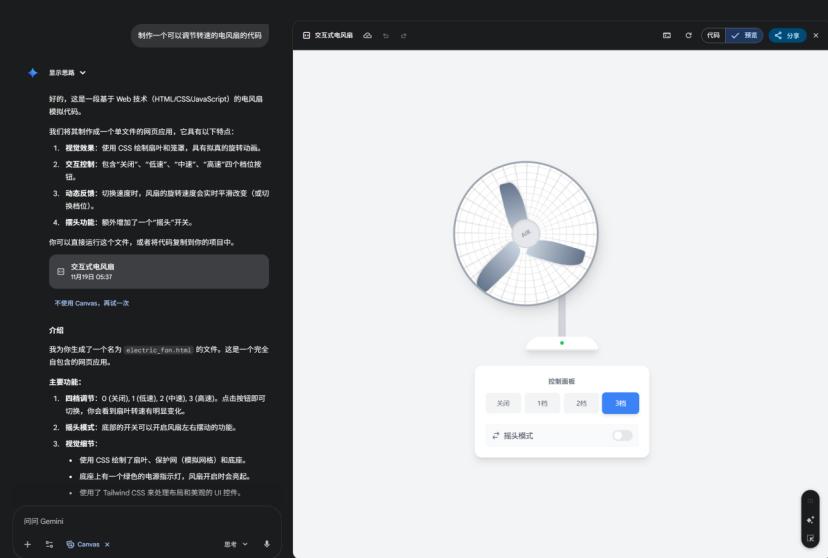
Серед офіційних прикладів також є візуалізація процесу ядерного синтезу.
Щодо способів взаємодії, Gemini 3 Pro отримав функцію “GenerativeUI” (генеративний інтерфейс). На відміну від традиційних AI-асистентів, які повертають лише текстові відповіді, ця система може автоматично створювати індивідуальні макети інтерфейсу залежно від запиту.
Наприклад, якщо користувач задає питання про квантові обчислення, система може створити інтерактивний інтерфейс із поясненнями, динамічними графіками та посиланнями на наукові статті.
Для різної аудиторії на одне й те саме питання система створює різні дизайни інтерфейсу. Наприклад, пояснення для дітей буде більш милим, а для дорослих — лаконічним і зрозумілим.
У Google Labs функція Visual Layout демонструє такі інтерфейси: користувачі отримують макети у стилі журналу з зображеннями, модулями та налаштовуваними елементами UI.
Також презентовано систему агентів під назвою Gemini Agent, яка наразі перебуває на стадії експерименту. Вона може виконувати багатокрокові завдання та підключатися до Gmail, Google Calendar і Reminders.
У сценарії керування поштою система може автоматично фільтрувати листи, позначати пріоритети та створювати чернетки відповідей. Ще один сценарій — планування подорожі: користувач вказує місце й приблизний час, а система перевіряє календар, шукає рейси й готелі, додає план подорожі. Наразі ця функція доступна лише для користувачів Google AI Ultra у США.
У мультимодальній обробці Gemini 3 Pro побудований на архітектурі sparse mixture-of-experts, підтримує текст, зображення, аудіо та відео. Вікно контексту моделі — 1 мільйон токенів, що дозволяє обробляти довгі документи чи відео.
За тестами професора історії з Університету Лоріє (Канада) Марка Хамфріса, модель має 0,56% помилок при розпізнаванні рукописів XVIII століття — це на 50-70% менше, ніж у попередньої версії.
Google зазначає, що для навчання використовувалися відкриті документи з інтернету, код, зображення, аудіо та відео, а на етапі донавчання — технології підкріпленого навчання.
Google також випустив оптимізовану версію Gemini 3 Deep Think для складних задач із міркування. Зараз вона проходить оцінку безпеки й буде доступна для підписників Google AI Ultra найближчими тижнями.
У AI-режимі Google Search користувачі можуть натиснути вкладку “thinking”, щоб побачити процес міркування. Порівняно зі стандартним режимом, Deep Think виконує більше кроків аналізу перед відповіддю.
Крім офіційної інформації, я також порівняв Gemini 3 Pro із ChatGPT-5.1.
Перше порівняння — генерація зображень.
Підказка: згенеруй мені iPhone17
ChatGPT-5.1

Gemini 3 Pro

Суб'єктивно мені більше сподобався результат ChatGPT-5.1, тому в цьому раунді перемагає ChatGPT-5.1.
Друге порівняння — рівень агентів обох моделей.
Підказка: досліди для мене WeChat-акаунт "字母榜" і прокоментуй його рівень
GPT-5.1

Gemini 3 Pro

Хоча суб'єктивно мені більше подобається інтерпретація Gemini 3 Pro, але вона занадто хвалебна, а ChatGPT-5.1 вказує на недоліки, що виглядає об'єктивніше й реальніше.
Останнє — це навички кодування, на які зараз звертають найбільшу увагу всі великі моделі.
Я вибрав проект із GitHub, який зараз дуже популярний — LightRAG. Він інтегрує графові структури для покращення контекстної обізнаності й ефективного пошуку інформації, що дозволяє досягти більшої точності та швидшого часу відгуку. Посилання на проект
Підказка: розкажи мені про цей проект
GPT-5.1

Gemini 3 Pro

Водночас Gemini 3 Pro отримав високу оцінку від професіоналів галузі.


02
Хоча реліз Gemini 3 Pro був дуже скромним, насправді Google готувався до нього досить довго.
На конференції з фінансових результатів за третій квартал CEO Google Сундар Пічаї сказав: “Gemini 3 Pro буде випущено у 2025 році.” Жодної конкретної дати, жодних деталей — так почалася велика маркетингова кампанія у сфері технологій.
Google постійно подавав сигнали, щоб AI-спільнота залишалася в напрузі, але так і не назвав жодної точної дати релізу.
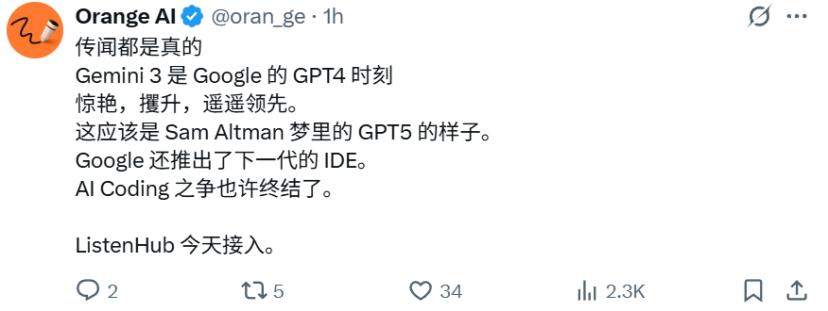
З жовтня почали з'являтися різні “випадкові витоки”. З 23 жовтня поширювався скріншот внутрішнього календаря з позначкою “Gemini 3 Pro Release” на 12 листопада.
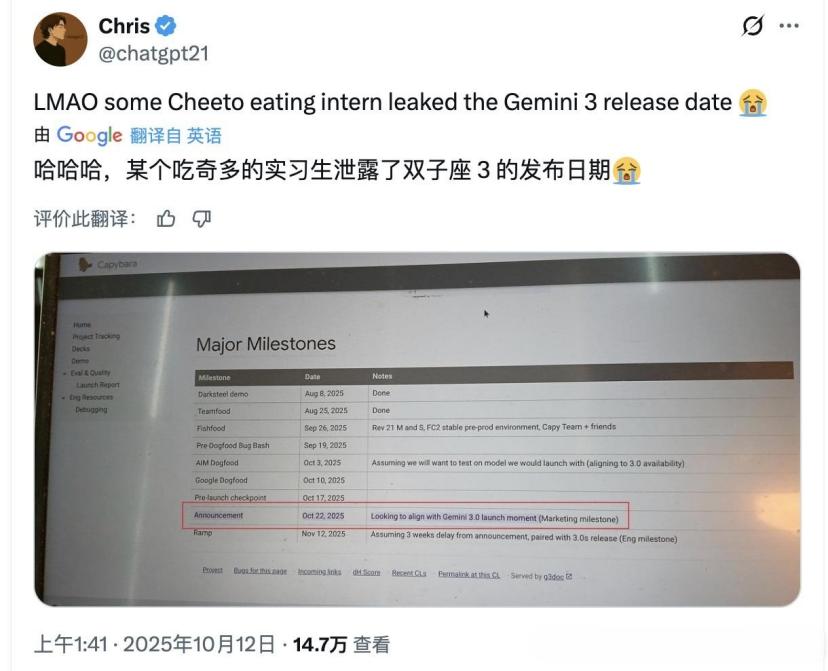
Пильні розробники також помітили у Vertex AI API згадку “gemini-3-pro-preview-11-2025”.
Далі на Reddit і X почали з'являтися різні скріншоти. Дехто стверджував, що бачив нову модель у Gemini Canvas, інші знаходили незвичні позначки моделі в мобільних додатках.
Потім у соцмережах почали поширювати ось ці тестові дані.
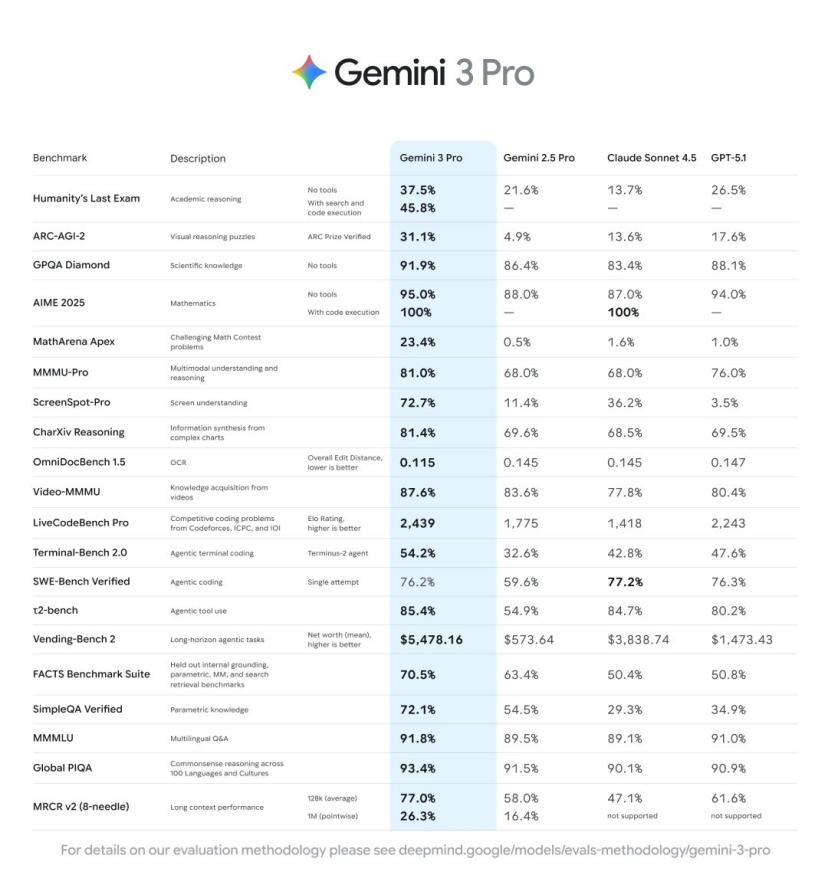
Ці “витоки” здаються випадковими, але насправді це була ретельно спланована підготовка.
Кожен витік вчасно демонстрував якусь ключову можливість Gemini 3 Pro, кожна дискусія піднімала очікування ще вище. А офіційні акаунти Google поводилися загадково: репостили обговорення, використовували фрази на кшталт “незабаром”, а керівники Google AI навіть відповідали на твіти про дату релізу двома емодзі “think”, але так і не називали точну дату.
Після майже місяця підготовки Google нарешті презентував свіжий Gemini 3 Pro. Однак, попри потужність Gemini 3 Pro, частота оновлень Google викликає занепокоєння.
Ще у березні цього року Google випустив прев'ю Gemini 2.5 Pro, потім — прев'ю Gemini 2.5 Flash та інші похідні версії. До появи Gemini 3 Pro серія Gemini не отримувала жодного оновлення версії.
Але конкуренти Google не чекали на Gemini.
OpenAI 7 серпня випустив GPT-5, а 12 листопада оновив його до GPT-5.1. За цей час OpenAI також презентував власний AI-браузер Atlas, націлений на головний ринок Google.
Anthropic оновлювався ще частіше: 24 лютого — Claude 3.7 Sonnet (перший гібридний reasoning-модель), 22 травня — Claude Opus 4 і Sonnet 4, 5 серпня — Claude Opus 4.1, 29 вересня — Claude Sonnet 4.5, 15 жовтня — Claude Haiku 4.5.
Ця серія атак застала Google зненацька, але наразі компанія втрималася.

03
Головна причина, чому Google витратив 8 місяців на оновлення Gemini 3 Pro, ймовірно, полягає у кадрових змінах.
У липні-серпні 2025 року Microsoft здійснила масштабний “кадровий рейд” проти Google, переманивши понад 20 ключових експертів і топ-менеджерів DeepMind.
Серед них — старший директор з продукту DeepMind Дейв Сітрон (Dave Citron), який відповідав за впровадження ключових AI-продуктів, а також віце-президент з інженерії Gemini Амар Субраманья (Amar Subramanya), один із головних інженерів моделі Gemini у Google.
З іншого боку, команда Nano Banana від Google зазначала, що після релізу Gemini 2.5 Pro компанія довго зосереджувалася на AI-генерації зображень, що сповільнило оновлення базових моделей.
Google вважає, що лише подолавши три ключові проблеми генерації зображень — character consistency (послідовність персонажів), in-context editing (редагування в контексті) та text rendering (відображення тексту), можна покращити роботу базових моделей.
Команда Nano Banana підкреслює: модель має не лише “гарно малювати”, а й “розуміти людську мову” та “бути керованою”, щоб AI-генерація зображень дійсно стала комерційною.
Якщо озирнутися на Gemini 3 Pro, це гідна відповідь, але на цьому AI-полі бою “задовільно” вже недостатньо.
Оскільки Google вирішив здати роботу саме зараз, компанія має бути готовою до найсуворіших оцінок — від користувачів і розробників, яких вже розбалували конкуренти. Наступні місяці — це не змагання параметрів моделей, а боротьба за інтеграцію екосистем. Цьому слону доведеться не лише навчитися танцювати, а й танцювати швидше за всіх.



