Nuevo artículo de Vitalik: El posible futuro del protocolo de Ethereum The Verge

De hecho, necesitaremos varios años para obtener una prueba de validez del consenso de Ethereum.
De hecho, necesitaremos varios años para obtener pruebas de validez del consenso de Ethereum.
Título original: 《Possible futures of the Ethereum protocol, part 4: The Verge》
Autor: Vitalik Buterin
Traducción: Mensh, ChainCatcher
Agradecimientos especiales a Justin Drake, Hsia-wei Wanp, Guillaume Ballet, Icinacio, Rosh Rudolf, Lev Soukhanoy, Ryan Sean Adams y Uma Roy por sus comentarios y revisión.
Una de las funciones más poderosas de la blockchain es que cualquiera puede ejecutar un nodo en su propio ordenador y verificar la corrección de la cadena. Incluso si 9596 nodos que ejecutan el consenso de la cadena (PoW, PoS) acuerdan inmediatamente cambiar las reglas y comienzan a producir bloques bajo las nuevas reglas, cualquier persona que ejecute un nodo de validación completa rechazará aceptar la cadena. Los mineros que no pertenezcan a este grupo conspirador se agruparán automáticamente en una cadena que siga las reglas antiguas y continuarán construyendo sobre esa cadena, y los usuarios que validen completamente seguirán esa cadena.
Esta es la diferencia clave entre blockchain y los sistemas centralizados. Sin embargo, para que esta característica se mantenga, ejecutar un nodo de validación completa debe ser realmente factible para un número suficiente de personas. Esto aplica tanto para los creadores de bloques (porque si no validan la cadena, no están contribuyendo a la ejecución de las reglas del protocolo), como para los usuarios comunes. Hoy en día, ejecutar un nodo en un portátil de consumo (incluido el portátil que se usó para escribir este artículo) es posible, pero difícil de lograr. The Verge pretende cambiar esta situación, haciendo que el coste computacional de validar completamente la cadena sea bajo, de modo que cada monedero móvil, monedero de navegador e incluso reloj inteligente realicen la validación por defecto.
Hoja de ruta de The Verge 2023
Originalmente, "Verge" se refería a trasladar el almacenamiento del estado de Ethereum a árboles Verkle, una estructura arbórea que permite pruebas más compactas y la validación sin estado de los bloques de Ethereum. Un nodo puede validar un bloque de Ethereum sin almacenar ningún estado de Ethereum (saldos de cuentas, código de contratos, almacenamiento, etc.) en su disco duro, a cambio de gastar unos cientos de KB de datos de prueba y unos cientos de milisegundos adicionales para validar una prueba. Hoy en día, Verge representa una visión más amplia, centrada en lograr la máxima eficiencia de recursos en la validación de la cadena de Ethereum, que incluye no solo la tecnología de validación sin estado, sino también el uso de SNARKs para validar toda la ejecución de Ethereum.
Además de la atención a largo plazo en la validación SNARK de toda la cadena, otro nuevo problema está relacionado con si los árboles Verkle son la mejor tecnología. Los árboles Verkle son vulnerables a ataques de computadoras cuánticas, por lo que si reemplazamos los actuales árboles Merkle Patricia KECCAK por árboles Verkle, más adelante tendremos que volver a reemplazar el árbol. El método de auto-reemplazo de los árboles Merkle es saltarse directamente el uso de ramas Merkle y usar STARK, insertándolo en un árbol binario. Históricamente, debido a la sobrecarga y complejidad técnica, este método se consideraba inviable. Sin embargo, recientemente hemos visto a Starkware probar 1.7 millones de hashes Poseidon por segundo en un portátil, y gracias a tecnologías como GKB, el tiempo de prueba de hashes "tradicionales" también se está reduciendo rápidamente. Por lo tanto, en el último año, "Verge" se ha vuelto más abierto, con varias posibilidades.
The Verge: Objetivos clave
- Cliente sin estado: el espacio de almacenamiento requerido para un cliente de validación completa y nodos marcados no debe superar unos pocos GB.
- (A largo plazo) Validación completa de la cadena (consenso y ejecución) en un reloj inteligente. Descargar algunos datos, validar el SNARK, listo.
En este capítulo
- Cliente sin estado: ¿Verkle o STARKs?
- Pruebas de validez de la ejecución EVM
- Pruebas de validez del consenso
Validación sin estado: ¿Verkle o STARKs?
¿Qué problema queremos resolver?
Hoy en día, los clientes de Ethereum necesitan almacenar cientos de gigabytes de datos de estado para validar bloques, y esta cantidad aumenta cada año. Los datos de estado originales aumentan unos 30GB al año, y cada cliente debe almacenar datos adicionales para actualizar eficientemente los tríos.
Esto reduce el número de usuarios capaces de ejecutar nodos de validación completa de Ethereum: aunque existen discos duros grandes capaces de almacenar todo el estado de Ethereum e incluso años de historia, los ordenadores que la gente compra por defecto suelen tener solo unos cientos de gigabytes de almacenamiento. El tamaño del estado también introduce una gran fricción en el proceso de establecer un nodo por primera vez: el nodo necesita descargar todo el estado, lo que puede llevar horas o días. Esto genera varios efectos en cadena. Por ejemplo, aumenta considerablemente la dificultad para que los creadores de nodos actualicen su configuración. Técnicamente, se puede hacer sin tiempo de inactividad: iniciar un nuevo cliente, esperar a que se sincronice, luego apagar el cliente antiguo y transferir las claves, pero en la práctica esto es muy complejo técnicamente.
¿Cómo funciona?
La validación sin estado es una técnica que permite a los nodos validar bloques sin poseer todo el estado. En su lugar, cada bloque viene acompañado de un testigo, que incluye: (i) los valores, código, saldos y almacenamiento en ubicaciones específicas del estado que el bloque accederá; (ii) pruebas criptográficas que demuestran que estos valores son correctos.
En la práctica, implementar la validación sin estado requiere cambiar la estructura del árbol de estado de Ethereum. Esto se debe a que el actual árbol Merkle Patricia es extremadamente poco amigable para cualquier esquema de prueba criptográfica, especialmente en el peor de los casos. Esto aplica tanto para las ramas Merkle "originales" como para la posibilidad de "envolverlas" en STARK. La principal dificultad proviene de algunas debilidades del MPT:
1. Es un árbol de seis ramas (es decir, cada nodo tiene 16 hijos). Esto significa que, en un árbol de tamaño N, una prueba requiere en promedio 32*(16-1)*log16(N) = 120*log2(N) bytes, o aproximadamente 3840 bytes en un árbol de 2^32 elementos. Para un árbol binario, solo se necesitan 32*(2-1)*log2(N) = 32*log2(N) bytes, o aproximadamente 1024 bytes.
2. El código no está merkleizado. Esto significa que para demostrar cualquier acceso al código de una cuenta, se debe proporcionar todo el código, hasta 24000 bytes.
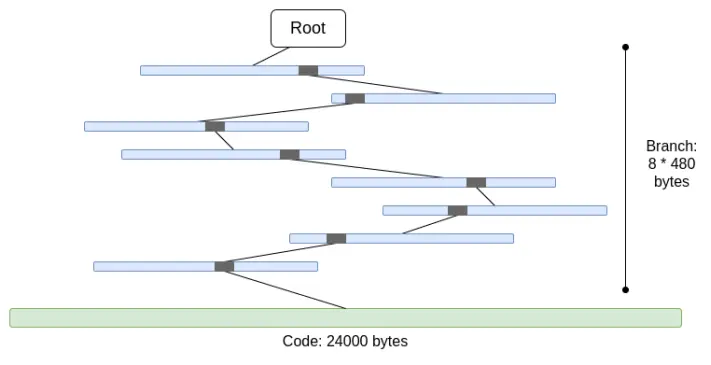
Podemos calcular el peor caso de la siguiente manera:
30000000 gas / 2400 (costo de lectura de cuenta fría) * (5 * 488 + 24000) = 330000000 bytes
El costo de las ramas se reduce ligeramente (usando 5*480 en lugar de 8*480), porque cuando hay muchas ramas, la parte superior se repite. Pero aun así, la cantidad de datos a descargar en un solo intervalo es completamente irreal. Si intentamos envolverlo en STARK, nos encontramos con dos problemas: (i) KECCAK no es amigable para STARK; (ii) 330MB de datos significa que debemos probar 5 millones de llamadas a la función round de KECCAK, lo que podría ser imposible de probar para cualquier hardware excepto el de consumo más potente, incluso si logramos hacer que la prueba STARK de KECCAK sea más eficiente.
Si reemplazamos directamente el árbol hexadecimal por un árbol binario y merkleizamos adicionalmente el código, el peor caso se convierte aproximadamente en 30000000/2400*32*(32-14+8) = 10400000 bytes (14 es la resta de bits redundantes para 2^14 ramas, y 8 es la longitud de la prueba para la hoja del bloque de código). Cabe señalar que esto requiere cambiar el costo de gas, cobrando por cada bloque de código individual; EIP-4762 lo hace así. 10.4 MB es mucho mejor, pero para muchos nodos, sigue siendo demasiados datos para descargar en un solo intervalo. Por lo tanto, necesitamos introducir técnicas más potentes. En este sentido, hay dos soluciones líderes: árboles Verkle y árboles hash binarios con STARK.
Árboles Verkle
Los árboles Verkle utilizan compromisos vectoriales basados en curvas elípticas para pruebas más cortas. La clave es que, independientemente del ancho del árbol, cada parte de la prueba correspondiente a una relación padre-hijo tiene solo 32 bytes. La única limitación al ancho del árbol es que, si el árbol es demasiado ancho, la eficiencia computacional de la prueba disminuye. La implementación propuesta para Ethereum tiene un ancho de 256.
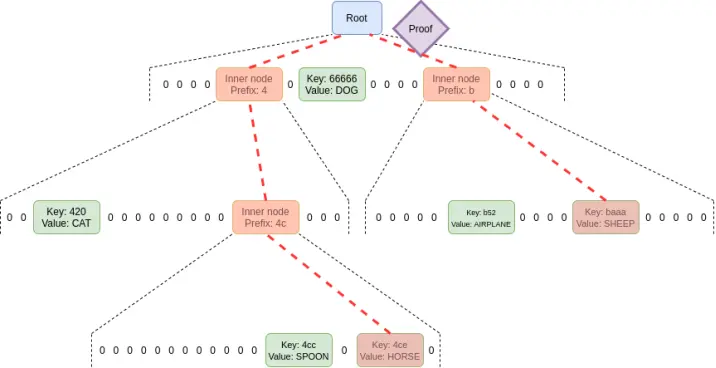
Por lo tanto, el tamaño de una sola rama en la prueba se convierte en 32 - log256(N) = 4*log2(N) bytes. Así, el tamaño máximo teórico de la prueba es aproximadamente 30000000 / 2400 *32* (32 -14 + 8) / 8 = 130000 bytes (debido a la distribución desigual de los bloques de estado, el cálculo real varía ligeramente, pero como primera aproximación es válido).
Además, en todos los ejemplos anteriores, este "peor caso" no es el peor: un caso aún peor es que un atacante "mine" dos direcciones con un prefijo común largo en el árbol y lea datos de una de ellas, lo que podría duplicar la longitud de la rama en el peor caso. Pero incluso así, la longitud máxima de la prueba de un árbol Verkle sería de 2.6MB, lo que coincide básicamente con los datos de verificación en el peor caso actual.
También aprovechamos esta observación para otra cosa: hacemos que el coste de acceder a espacios de almacenamiento "adyacentes" sea muy bajo: ya sea muchos bloques de código del mismo contrato o ranuras de almacenamiento adyacentes. EIP-4762 define la adyacencia y solo cobra 200 gas por acceso adyacente. En el caso de acceso adyacente, el tamaño de la prueba en el peor caso se convierte en 30000000 / 200*32 - 4800800 bytes, lo que sigue estando dentro de un rango tolerable. Si por seguridad queremos reducir este valor, podemos aumentar ligeramente el coste del acceso adyacente.
Árbol hash binario con STARK
El principio de esta técnica es evidente: simplemente se hace un árbol binario, se obtiene una prueba máxima de 10.4 MB, se prueban los valores en el bloque y luego se reemplaza la prueba por una prueba STARK. Así, la prueba solo contiene los datos probados, más una sobrecarga fija de 100-300kB del STARK real.
El principal desafío aquí es el tiempo de verificación. Podemos hacer un cálculo similar al anterior, pero en lugar de bytes, calculamos hashes. Un bloque de 10.4 MB implica 330000 hashes. Si sumamos la posibilidad de que un atacante "mine" direcciones con prefijos comunes largos en el árbol, el peor caso sería de unos 660000 hashes. Por lo tanto, si podemos probar 200,000 hashes por segundo, no hay problema.
En portátiles de consumo usando la función hash Poseidon, estos números ya se alcanzan, y Poseidon está diseñado específicamente para ser amigable con STARK. Sin embargo, el sistema Poseidon aún es relativamente inmaduro, por lo que muchos no confían en su seguridad. Por lo tanto, hay dos caminos realistas:
- Realizar rápidamente un gran análisis de seguridad de Poseidon y familiarizarse lo suficiente como para desplegarlo en L1
- Usar funciones hash más "conservadoras", como SHA256 o BLAKE
Para probar funciones hash conservadoras, el círculo STARK de Starkware solo puede probar 10-30k hashes por segundo en portátiles de consumo al momento de escribir esto. Sin embargo, la tecnología STARK está mejorando rápidamente. Incluso hoy, la tecnología basada en GKR muestra que esta velocidad puede aumentar al rango de 100-200k.
Casos de uso de testigos más allá de la validación de bloques
Además de la validación de bloques, hay otros tres casos de uso clave que requieren validación sin estado más eficiente:
- Mempool: cuando una transacción se transmite, los nodos en la red P2P deben verificar su validez antes de retransmitirla. Hoy en día, la verificación incluye la firma y comprobar que el saldo es suficiente y el prefijo correcto. En el futuro (por ejemplo, con abstracción de cuentas nativa como EIP-7701), esto podría implicar ejecutar código EVM que acceda a algún estado. Si el nodo es sin estado, la transacción debe incluir pruebas de los objetos de estado.
- Listas de inclusión: esta es una función propuesta que permite a los validadores de prueba de participación (posiblemente pequeños y no complejos) forzar la inclusión de transacciones en el siguiente bloque, independientemente de la voluntad de los constructores de bloques (posiblemente grandes y complejos). Esto debilita la capacidad de los poderosos de manipular la cadena retrasando transacciones. Sin embargo, requiere que los validadores puedan verificar la validez de las transacciones en la lista de inclusión.
- Clientes ligeros: si queremos que los usuarios accedan a la cadena a través de monederos (como Metamask, Rainbow, Rabby, etc.), necesitan ejecutar un cliente ligero (como Helios). El módulo central de Helios proporciona a los usuarios la raíz de estado verificada. Para una experiencia completamente sin confianza, los usuarios deben proporcionar pruebas para cada llamada RPC (por ejemplo, para una solicitud de llamada de Ethereum, el usuario debe probar todos los estados accedidos durante la llamada).
Todos estos casos de uso tienen en común que requieren bastantes pruebas, pero cada una es pequeña. Por lo tanto, las pruebas STARK no tienen mucho sentido para ellos; en cambio, lo más realista es usar ramas Merkle directamente. Otra ventaja de las ramas Merkle es que son actualizables: dada una prueba de un objeto de estado con raíz en el bloque B, si se recibe un sub-bloque B2 y su testigo, se puede actualizar la prueba para que tenga raíz en B2. Las pruebas Verkle también son actualizables de forma nativa.
¿Qué relación tiene con la investigación existente?
- Verkle trees
- Artículo original de John Kuszmaul sobre árboles Verkle
- Starkware
- Poseidon2 paper
- Ajtai (funciones hash rápidas alternativas basadas en la dureza de retículas)
- Verkle.info
¿Qué más se puede hacer?
El trabajo principal restante es
1. Más análisis sobre las consecuencias de EIP-4762 (cambios en el coste de gas sin estado)
2. Más trabajo en completar y probar el programa de transición, que es la parte principal de la complejidad de cualquier implementación sin estado
3. Más análisis de seguridad de Poseidon, Ajtai y otras funciones hash "amigables con STARK"
4. Desarrollar aún más funciones de protocolo STARK ultraeficientes para hashes "conservadores" (o "tradicionales"), por ejemplo, basadas en Binius o GKR.
Además, pronto decidiremos entre tres opciones: (i) árboles Verkle, (ii) funciones hash amigables con STARK y (iii) funciones hash conservadoras. Sus características se resumen en la siguiente tabla:
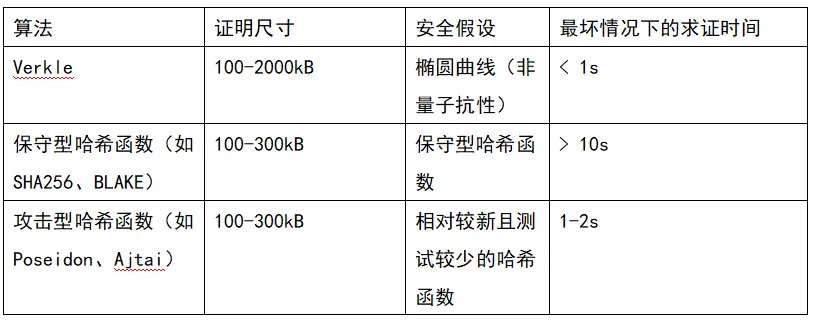
Además de estos "números principales", hay otras consideraciones importantes:
- Hoy en día, el código de los árboles Verkle ya es bastante maduro. Usar cualquier otro código que no sea Verkle retrasaría el despliegue, probablemente retrasando un hard fork. Esto no es un problema, especialmente si necesitamos tiempo adicional para análisis de funciones hash o implementación de validadores, o si tenemos otras funciones importantes que queremos incluir antes en Ethereum.
- Actualizar la raíz de estado usando hashes es más rápido que usando árboles Verkle. Esto significa que los métodos basados en hashes pueden reducir el tiempo de sincronización de los nodos completos.
- Los árboles Verkle tienen interesantes propiedades de actualización de testigos: los testigos Verkle son actualizables. Esta propiedad es útil para mempool, listas de inclusión y otros casos de uso, y también puede ayudar a mejorar la eficiencia de la implementación: si se actualiza un objeto de estado, se puede actualizar el testigo de la penúltima capa sin leer el contenido de la última capa.
- Los árboles Verkle son más difíciles de probar con SNARK. Si queremos reducir el tamaño de la prueba a unos pocos miles de bytes, las pruebas Verkle presentan algunas dificultades. Esto se debe a que la verificación de la prueba Verkle introduce muchas operaciones de 256 bits, lo que requiere que el sistema de pruebas tenga una gran sobrecarga o una estructura interna personalizada con una parte de prueba Verkle de 256 bits. Esto no es un problema para la validación sin estado en sí, pero sí añade más dificultades.
Si queremos obtener la capacidad de actualización de testigos Verkle de forma segura contra ataques cuánticos y razonablemente eficiente, otra posible vía es usar árboles Merkle basados en retículas.
Si en el peor de los casos la eficiencia del sistema de pruebas no es suficiente, también podemos utilizar la herramienta inesperada del gas multidimensional para compensar esta deficiencia: establecer límites de gas separados para (i) calldata; (ii) computación; (iii) acceso al estado y posiblemente otros recursos diferentes. El gas multidimensional aumenta la complejidad, pero a cambio limita más estrictamente la relación entre el caso promedio y el peor caso. Con gas multidimensional, el número máximo de ramas que se deben probar podría reducirse de 12500 a, por ejemplo, 3000. Esto haría que BLAKE3 fuera (apenas) suficiente incluso hoy.
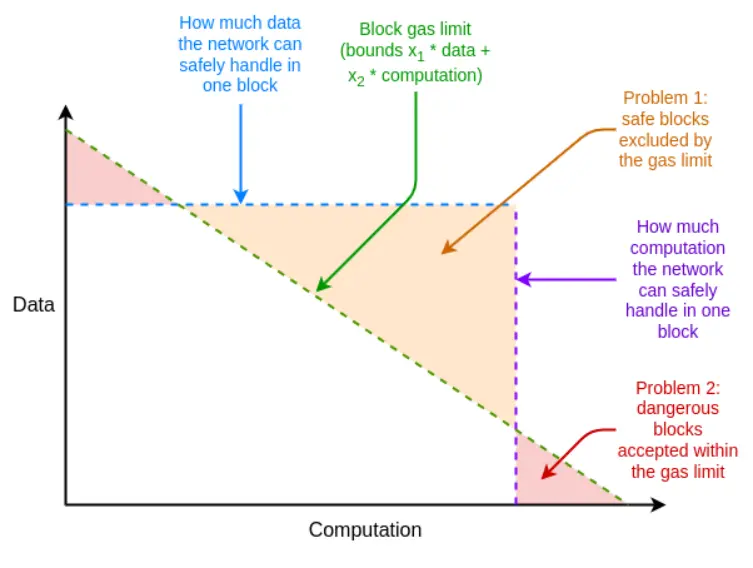
El gas multidimensional permite que los límites de recursos de los bloques se acerquen más a los límites de recursos del hardware subyacente
Otra herramienta inesperada es retrasar el cálculo de la raíz de estado hasta el intervalo posterior al bloque. Así, tenemos 12 segundos completos para calcular la raíz de estado, lo que significa que incluso en el caso más extremo, solo se necesitan 60000 hashes por segundo, lo que nuevamente hace que BLAKE3 sea apenas suficiente.
La desventaja de este método es que aumenta la latencia del cliente ligero en un intervalo, aunque hay técnicas más ingeniosas que pueden reducir esta latencia a solo la latencia de generación de la prueba. Por ejemplo, la prueba puede transmitirse en la red tan pronto como cualquier nodo la genere, sin esperar al siguiente bloque.
¿Cómo interactúa con otras partes de la hoja de ruta?
Resolver el problema sin estado aumenta considerablemente la dificultad del staking individual. Si existen técnicas que reduzcan el saldo mínimo para el staking individual, como Orbit SSF o estrategias a nivel de aplicación como el staking en escuadrones, esto será más factible.
Si se introduce EOF al mismo tiempo, el análisis de gas multidimensional se vuelve más fácil. Esto se debe a que la mayor complejidad de ejecución del gas multidimensional proviene de manejar llamadas secundarias que no transmiten todo el gas del padre, mientras que EOF simplemente hace que tales llamadas sean ilegales, lo que trivializa el problema (y la abstracción de cuentas nativa proporcionará una alternativa dentro del protocolo para los principales casos de uso actuales de gas parcial).
Existe una sinergia importante entre la validación sin estado y la expiración histórica. Hoy en día, los clientes deben almacenar casi 1TB de datos históricos; estos datos son varias veces el tamaño de los datos de estado. Incluso si el cliente es sin estado, a menos que podamos liberar al cliente de almacenar datos históricos, el sueño de un cliente casi sin almacenamiento no se hará realidad. El primer paso en esta dirección es EIP-4444, que también significa almacenar datos históricos en torrents o en la Portal Network.
Pruebas de validez de la ejecución EVM
¿Qué problema queremos resolver?
El objetivo a largo plazo de la validación de bloques de Ethereum es claro: debería ser posible validar un bloque de Ethereum de la siguiente manera: (i) descargar el bloque, o incluso solo una pequeña parte de la muestra de disponibilidad de datos del bloque; (ii) validar una pequeña prueba de validez del bloque. Esto sería una operación de muy bajo consumo de recursos, que podría realizarse en clientes móviles, monederos de navegador e incluso en otra cadena (sin la parte de disponibilidad de datos).
Para lograr esto, se requieren pruebas SNARK o STARK tanto para (i) la capa de consenso (es decir, prueba de participación) como para (ii) la capa de ejecución (es decir, EVM). La primera es un desafío en sí misma y debe abordarse a medida que se mejora la capa de consenso (por ejemplo, para la finalidad de ranura única). La segunda requiere pruebas de ejecución EVM.
¿Qué es y cómo funciona?
Formalmente, en la especificación de Ethereum, la EVM se define como una función de transición de estado: tienes un estado anterior S, un bloque B, y calculas un estado posterior S' = STF(S, B). Si el usuario utiliza un cliente ligero, no posee S ni S' completos, ni siquiera E; en su lugar, tiene una raíz de estado anterior R, una raíz de estado posterior R' y un hash de bloque H.
- Entrada pública: raíz de estado anterior R, raíz de estado posterior R', hash de bloque H
- Entrada privada: cuerpo del bloque de programa B, objetos en el estado accedidos por el bloque Q, los mismos objetos después de ejecutar Q', pruebas de estado (como ramas Merkle) P
- Afirmación 1: P es una prueba válida que demuestra que Q contiene ciertas partes del estado representado por R
- Afirmación 2: Si se ejecuta STF en Q, (i) el proceso de ejecución solo accede a objetos dentro de Q, (ii) el bloque es válido, (iii) el resultado es Q'
- Afirmación 3: Si se recalcula la nueva raíz de estado usando la información de Q' y P, se obtiene R'
Si esto existe, se puede tener un cliente ligero que valide completamente la ejecución EVM de Ethereum. Esto hace que los recursos del cliente sean bastante bajos. Para lograr un cliente completamente validado de Ethereum, también se debe hacer lo mismo para el consenso.
Ya existen implementaciones de pruebas de validez para la computación EVM, y son ampliamente utilizadas en L2. Pero para que las pruebas de validez EVM sean viables en L1, aún queda mucho trabajo por hacer.
¿Qué relación tiene con la investigación existente?
- EFPSE ZK-EVM (descontinuado por mejores opciones)
- Zeth, que compila EVM en RISC-0 ZK-VM
- Proyecto de verificación formal de ZK-EVM
¿Qué más se puede hacer?
Hoy en día, las pruebas de validez de los sistemas de contabilidad electrónica son insuficientes en dos aspectos: seguridad y tiempo de verificación.
Una prueba de validez segura debe garantizar que el SNARK realmente verifica el cálculo de la EVM y que no existen vulnerabilidades. Las dos principales técnicas para mejorar la seguridad son los múltiples verificadores y la verificación formal. Múltiples verificadores significa tener varias implementaciones independientes de pruebas de validez, como tener varios clientes; si un bloque es probado por un subconjunto suficientemente grande de estas implementaciones, el cliente aceptará el bloque. La verificación formal implica usar herramientas normalmente utilizadas para demostrar teoremas matemáticos, como Lean4, para demostrar que la prueba de validez solo acepta ejecuciones correctas de la especificación EVM subyacente (por ejemplo, la semántica K de EVM o la especificación de la capa de ejecución de Ethereum escrita en python (EELS)).
Un tiempo de verificación suficientemente rápido significa que cualquier bloque de Ethereum puede ser verificado en menos de 4 segundos. Hoy estamos lejos de ese objetivo, aunque estamos más cerca de lo que imaginábamos hace dos años. Para lograrlo, necesitamos avanzar en tres direcciones:
- Paralelización: el verificador EVM más rápido actualmente puede probar un bloque de Ethereum en promedio en 15 segundos. Esto se logra paralelizando entre cientos de GPU y luego agregando su trabajo al final. En teoría, sabemos cómo crear un verificador EVM que pruebe el cálculo en tiempo O(log(N)): hacer que una GPU realice cada paso y luego hacer un "árbol de agregación":
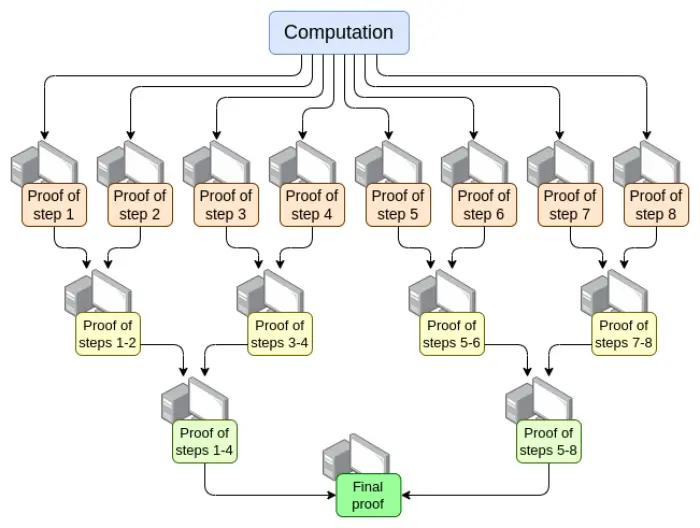
Implementar esto tiene desafíos. Incluso en el peor de los casos, es decir, una transacción muy grande ocupa todo el bloque, la división del cálculo no puede hacerse por transacción, sino por opcode (opcode de EVM o de la máquina virtual subyacente como RISC-V). Garantizar que la "memoria" de la máquina virtual se mantenga coherente entre las diferentes partes de la prueba es un desafío clave en la implementación. Sin embargo, si logramos esta prueba recursiva, sabemos que, incluso sin otras mejoras, al menos el problema de latencia del verificador está resuelto.
- Optimización del sistema de pruebas: nuevos sistemas de pruebas como Orion, Binius, GRK y otros probablemente reducirán aún más el tiempo de verificación de cálculos generales.
- Otros cambios en el coste de gas de la EVM: muchas cosas en la EVM pueden optimizarse para beneficiar a los verificadores, especialmente en el peor de los casos. Si un atacante puede construir un bloque que bloquee al verificador durante diez minutos, entonces no basta con poder probar un bloque normal de Ethereum en 4 segundos. Los cambios necesarios en la EVM pueden dividirse en las siguientes categorías:
- Cambios en el coste de gas: si una operación tarda mucho en probarse, incluso si es relativamente rápida de calcular, debería tener un coste de gas alto. EIP-7667 se propuso para abordar este problema, aumentando considerablemente el coste de gas de las funciones hash (tradicionales), ya que sus opcodes y precompilados son relativamente baratos. Para compensar este aumento, podemos reducir el coste de gas de los opcodes EVM con bajo coste de prueba, manteniendo el rendimiento promedio.
- Sustitución de estructuras de datos: además de reemplazar el árbol de estado por un método más amigable para STARK, también debemos reemplazar la lista de transacciones, el árbol de recibos y otras estructuras costosas de probar. El EIP de Etan Kissling que mueve las estructuras de transacciones y recibos a SSZ es un paso en esa dirección.
Además, las dos herramientas mencionadas en la sección anterior (gas multidimensional y raíz de estado retrasada) también pueden ayudar aquí. Sin embargo, cabe señalar que, a diferencia de la validación sin estado, el uso de estas dos herramientas significa que ya tenemos suficiente tecnología para hacer lo que necesitamos actualmente, pero incluso con estas técnicas, la validación completa ZK-EVM requiere más trabajo, aunque menos que antes.
Un punto no mencionado anteriormente es el hardware del verificador: usar GPU, FPGA y ASIC para generar pruebas más rápido. Fabric Cryptography, Cysic y Accseal son tres empresas que han avanzado en esto. Esto es muy valioso para L2, pero es poco probable que sea decisivo para L1, ya que se desea que L1 permanezca altamente descentralizado, lo que significa que la generación de pruebas debe estar al alcance razonable de los usuarios de Ethereum y no depender de cuellos de botella de hardware de una sola empresa. L2 puede hacer compensaciones más agresivas.
En estos campos, aún queda mucho por hacer:
- La paralelización de pruebas requiere que diferentes partes del sistema de pruebas puedan "compartir memoria" (como tablas de búsqueda). Sabemos cómo hacerlo, pero hay que implementarlo.
- Necesitamos más análisis para encontrar el conjunto ideal de cambios en el coste de gas que minimicen el tiempo de verificación en el peor caso.
- Necesitamos más trabajo en los sistemas de pruebas
Los posibles costes son:
- Seguridad vs tiempo del verificador: elegir funciones hash más agresivas, sistemas de pruebas más complejos o suposiciones de seguridad más agresivas u otros diseños puede reducir el tiempo del verificador.
- Descentralización vs tiempo del verificador: la comunidad debe acordar las "especificaciones" del hardware del verificador objetivo. ¿Está bien que los verificadores sean entidades a gran escala? ¿Queremos que un portátil de gama alta pueda probar un bloque de Ethereum en 4 segundos? ¿O algo intermedio?
- Grado de ruptura de la compatibilidad hacia atrás: otras deficiencias pueden compensarse con cambios más agresivos en el coste de gas, pero esto podría aumentar desproporcionadamente el coste de ciertas aplicaciones, obligando a los desarrolladores a reescribir y volver a desplegar código para mantener la viabilidad económica. Igualmente, estas dos herramientas tienen su propia complejidad y desventajas.
¿Cómo interactúa con otras partes de la hoja de ruta?
La tecnología central necesaria para lograr pruebas de validez EVM en L1 se comparte en gran medida con otros dos campos:
- Pruebas de validez en L2 (es decir, "ZK rollup")
- Método sin estado de "prueba hash binaria STARK"
Si se implementan con éxito pruebas de validez en L1, finalmente se podrá lograr el staking individual sencillo: incluso los ordenadores más débiles (incluidos móviles o relojes inteligentes) podrán hacer staking. Esto aumenta aún más el valor de resolver otras restricciones del staking individual (como el mínimo de 32ETH).
Además, las pruebas de validez EVM en L1 pueden aumentar considerablemente el límite de gas de L1.
Pruebas de validez del consenso
¿Qué problema queremos resolver?
Si queremos validar completamente un bloque de Ethereum con SNARK, la ejecución de la EVM no es la única parte que debemos probar. También debemos probar el consenso, es decir, la parte del sistema que maneja depósitos, retiros, firmas, actualizaciones de saldo de validadores y otros elementos de la prueba de participación de Ethereum.
El consenso es mucho más simple que la EVM, pero enfrenta el desafío de que no tenemos convolución EVM en L2, por lo que, de todos modos, la mayor parte del trabajo debe hacerse. Por lo tanto, cualquier implementación de pruebas del consenso de Ethereum debe hacerse "desde cero", aunque el sistema de pruebas en sí puede aprovechar trabajo compartido.
¿Qué es y cómo funciona?
La Beacon Chain se define como una función de transición de estado, igual que la EVM. La función de transición de estado se compone principalmente de tres partes:
- ECADD (para verificar firmas BLS)
- Emparejamiento (para verificar firmas BLS)
- Hash SHA256 (para leer y actualizar el estado)
En cada bloque, necesitamos probar 1-16 ECADD BLS12-381 por validador (puede ser más de uno, ya que una firma puede estar en varios conjuntos). Esto puede mitigarse con técnicas de precomputación de subconjuntos, por lo que podemos decir que cada validador solo necesita probar un ECADD BLS12-381. Actualmente, hay 30000 firmas de validadores por intervalo. En el futuro, con la finalidad de ranura única, esto podría cambiar en dos direcciones: si tomamos la ruta "fuerza bruta", el número de validadores por intervalo podría aumentar a 1 millón. Al mismo tiempo, si usamos Orbit SSF, el número de validadores se mantendrá en 32768 o incluso bajará a 8192.
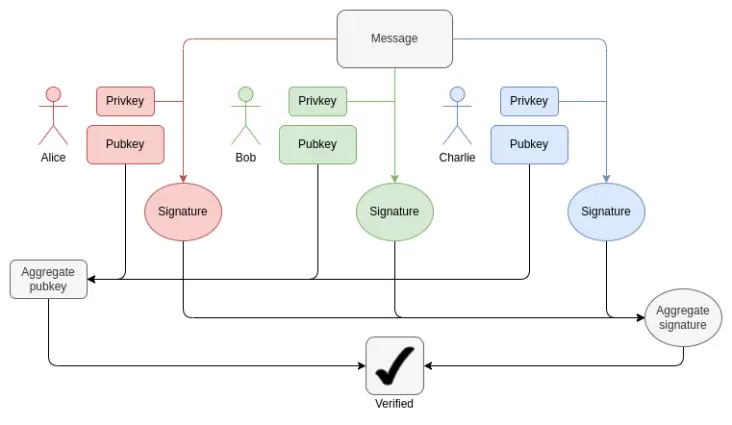
Cómo funciona la agregación BLS: verificar la firma total solo requiere un ECADD por participante, no un ECMUL. Pero 30000 ECADD siguen siendo una gran cantidad de pruebas.
En cuanto al emparejamiento, actualmente hay hasta 128 pruebas por intervalo, lo que significa que se deben verificar 128 emparejamientos. Con ElP-7549 y más modificaciones, esto puede reducirse a 16 por intervalo. Los emparejamientos son pocos, pero su coste es altísimo: cada ejecución (o prueba) de emparejamiento tarda miles de veces más que un ECADD.
Un gran desafío para probar operaciones BLS12-381 es que no hay una curva conveniente con orden igual al tamaño del campo BLS12-381, lo que añade una sobrecarga considerable a cualquier sistema de pruebas. Por otro lado, los árboles Verkle propuestos para Ethereum se construyen con la curva Bandersnatch, lo que hace que BLS12-381 sea la curva propia utilizada en el sistema SNARK para probar ramas Verkle. Una implementación sencilla puede probar 100 sumas G1 por segundo; para que la prueba sea lo suficientemente rápida, casi seguro se necesitarán técnicas inteligentes como GKR.
Para los hashes SHA256, el peor caso actual es el bloque de transición de época, donde se actualizan todo el árbol de balances cortos de validadores y muchos balances de validadores. El árbol de balances cortos de cada validador tiene solo un byte, por lo que hay 1 MB de datos que se vuelven a hashear. Esto equivale a 32768 llamadas SHA256. Si mil validadores tienen un saldo por encima o por debajo de un umbral, se deben actualizar los registros de validador, lo que equivale a mil ramas Merkle, por lo que pueden ser necesarias diez mil hashes. El mecanismo de barajado requiere 90 bits por validador (11 MB de datos), pero esto puede calcularse en cualquier momento de la época. Con finalidad de ranura única, estos números pueden variar. El barajado se vuelve innecesario, aunque Orbit podría restaurar esta necesidad en cierta medida.
Otro desafío es que se debe volver a obtener todo el estado de los validadores, incluidas las claves públicas, para verificar un bloque. Para 1 millón de validadores, solo leer las claves públicas requiere 48 millones de bytes, más las ramas Merkle. Esto requiere millones de hashes por época. Si debemos probar la validez de PoS, un método realista es algún tipo de cálculo verificable incremental: almacenar en el sistema de pruebas una estructura de datos separada optimizada para búsquedas eficientes y probar la actualización de esa estructura.
En resumen, hay muchos desafíos. Para abordarlos de la manera más eficiente, probablemente se requiera una profunda rediseño de la Beacon Chain, que podría coincidir con la transición a la finalidad de ranura única. Este rediseño podría incluir:
- Cambio de función hash: actualmente se usa SHA256 "completo", por lo que debido al relleno, cada llamada corresponde a dos llamadas a la función de compresión subyacente. Si cambiamos a la función de compresión SHA256, al menos duplicamos la eficiencia. Si cambiamos a Poseidon, podríamos obtener una ganancia de 100 veces, resolviendo todos nuestros problemas (al menos en cuanto a hashes): a 1.7 millones de hashes por segundo (54MB), incluso un millón de registros de validadores pueden "leerse" en la prueba en unos segundos.
- Si es Orbit, almacenar directamente los registros de validadores barajados: si se seleccionan 8192 o 32768 validadores como comité para un intervalo, se colocan directamente juntos en el estado, lo que permite leer todas las claves públicas de los validadores en la prueba con un mínimo de hashes. Esto también permite realizar todas las actualizaciones de balances de manera eficiente.
- Agregación de firmas: cualquier esquema de agregación de firmas de alto rendimiento implicará alguna forma de prueba recursiva, donde diferentes nodos de la red prueban subconjuntos de firmas intermedias. Esto distribuye naturalmente el trabajo de prueba entre varios nodos, reduciendo considerablemente la carga del "verificador final".
- Otros esquemas de firmas: para firmas Lamport+Merkle, se necesitan 256 + 32 hashes para verificar una firma; multiplicado por 32768 firmantes, son 9437184 hashes. Optimizando el esquema de firmas, este resultado puede mejorarse aún más por un pequeño factor constante. Si usamos Poseidon, esto puede probarse en un solo intervalo. Pero en la práctica, usar un esquema de agregación recursiva será más rápido.
¿Qué relación tiene con la investigación existente?
- Pruebas concisas de consenso de Ethereum (solo para el comité de sincronización)
- Helios en SP1 conciso
- Precompilado conciso BLS12-381
- Verificación de firmas agregadas BLS basada en Halo2
¿Qué más queda por hacer y cómo decidir?
De hecho, necesitaremos varios años para obtener pruebas de validez del consenso de Ethereum. Esto coincide aproximadamente con el tiempo necesario para lograr finalidad de ranura única, Orbit, modificar el algoritmo de firmas y el análisis de seguridad necesario para tener suficiente confianza en el uso de funciones hash "agresivas" como Poseidon. Por lo tanto, lo más sensato es abordar estos otros problemas y considerar la compatibilidad con STARK al mismo tiempo.
El principal equilibrio probablemente será en el orden de las operaciones, entre un enfoque más gradual de reforma de la capa de consenso de Ethereum y un enfoque más agresivo de "cambiar muchas cosas a la vez". Para la EVM, el enfoque gradual es razonable porque minimiza la interferencia con la compatibilidad hacia atrás. Para la capa de consenso, el impacto en la compatibilidad hacia atrás es menor, y repensar de manera más "integral" los detalles de cómo se construye la Beacon Chain para optimizar la compatibilidad con SNARK también tiene ventajas.
¿Cómo interactúa con otras partes de la hoja de ruta?
Al rediseñar a largo plazo el PoS de Ethereum, la compatibilidad con STARK debe ser una consideración principal, especialmente para la finalidad de ranura única, Orbit, cambios en el esquema de firmas y agregación de firmas.
Descargo de responsabilidad: El contenido de este artículo refleja únicamente la opinión del autor y no representa en modo alguno a la plataforma. Este artículo no se pretende servir de referencia para tomar decisiones de inversión.
También te puede gustar
La propuesta de Bitcoin para frenar el spam con un soft fork temporal genera debate entre los desarrolladores
BIP-444 solicita a los desarrolladores de Bitcoin que restrinjan la cantidad de datos arbitrarios que se pueden adjuntar a las transacciones en la red. Los partidarios están preocupados de que se pueda añadir contenido ilegal a Bitcoin tras la reciente actualización v30 Core, que eliminó los límites de datos OP_RETURN; los detractores dicen que la propuesta equivale a censura a nivel de protocolo. El cambio requeriría una soft fork de la blockchain y duraría aproximadamente un año, durante el cual los desarrolladores podrían evaluar soluciones a largo plazo.

El suministro ilíquido de Bitcoin disminuye mientras 62,000 BTC salen de las billeteras de holders a largo plazo: Glassnode
Según datos de Glassnode, alrededor de 62,000 BTC, valorados en 7 billions de dólares a precios actuales, han salido de las billeteras de holders a largo plazo desde mediados de octubre. Un suministro más líquido dificulta que el precio de Bitcoin suba sin una fuerte demanda externa.

Pronóstico del precio de Bitcoin: inversores apuestan 400 millones de dólares en BTC mientras Trump se reúne con Xi de China en Corea
El precio de Bitcoin repuntó a 113,800 dólares el domingo, registrando un aumento del 10% mientras los inversores trasladaban capital del oro a la exposición a BTC basada en DeFi.
Análisis del precio de Ethereum: los traders en corto de ETH despliegan 650 millones de dólares en apalancamiento antes de la reunión sobre aranceles entre Trump y China
El precio de Ethereum se recupera por encima de los $4,000 mientras los traders anticipan las próximas conversaciones arancelarias de Trump con Xi Jinping de China y el aumento de posiciones cortas.